Modelo de BERT¶
El modelo de BERT (Bidirectional Encoder Representations from Transformers) propone un modelo del lenguaje pre-entrenado que tome en consideración todo el contexto de una palabra. Para esto hace uso del enmascaramiento y los mecanismos de auto-atención de los Transformers. Sin embargo, este modelo se enfoca únicamente en el encoder, dejando de lado el decoder. Al hacer esto, el modelo obtenido es más simple que los modelos de Transformer encoder-decoder. El utilizar sólo el encoder está motivado por el hecho de que la salida del modelo serán las probabilidades de las representaciones del vocabulario de entrada. No existe un vocabulario de salida, por tanto, los mecanismos del decoder no son necesarios.
El modelo de BERT se basa en un modelo del lenguaje enmascarado, lo que permite que las representaciones obtenidas contengan información tanto del contexto a la izquierda como del contexto a la derecha, y las relaciones entre todos los elementos del contexto. Se proponen dos fases para obtener las representaciones a partir de BERT: 1) Pre-entrenar el modelo para obtener representaciones de los tokens en el corpus; y 2) ajuste fino (\textit{fine tuning}) de estas representaciones.
El pre-entrenamiento consiste en entrenar el modelo de BERT (el encoder del Transformer) en un modelo del lenguaje enmascarado. Esto implica que los datos del entrenamiento no están etiquetados y, por tanto, se trata de un modelo de aprendizaje no-supervisado (o auto-supervisado). Además de entrenar un modelo del lenguaje, se propone que en esta fase el modelo se entrene en una tarea de predicción de la siguiente secuencia; es decir, se entrenará el modelo para que sea capaz de predecir si, dada una segunda oración, esa oración es la oración que sigue a la oración actual o no. En este caso, se trata de una tarea supervisada, pero las etiquetas (es o no es la siguiente oración) se obtienen a partir de los datos de corpus, por lo que tampoco se requiere supervisión humana.
Por otra parte, el ajuste fino consiste en utilizar las representaciones obtenidas en el modelo de BERT para inicializar los parámetros de un modelo de aprendizaje que se enfoque en una tarea supervisada. En este caso, se trabajará con datos etiquetados. Para realizar un ajuste fino de los parámetros se tomará, por ejemplo, una tarea de detección de spam, donde se cuente con datos etiquetados (es o no es spam). Las representaciones de BERT se utilizarán para inicializar algunos de los parámetros del modelo: por ejemplo, pueden servir para iniciar una matriz de embeddings. De esta forma, las representaciones de BERT se ajustarán al problema en cuestión para, así, obtener nuevas representaciones que sean particulares de esa tarea.
Pre-entrenamiento¶
El pre-entrenamiento del modelo de BERT consiste en dos tareas:
\begin{description}
Sin embargo, este régimen de entrenamiento puede afectar al ajuste fino, puesto que la etiqueta Mask del modelo del lenguaje no aparecerá en las cadenas durante el proceso de ajuste-fino y por tanto las cadenas de entrada en el pre-entrenamiento y durante el ajuste fino pueden presentar diferencias. Para mitigar esto, los autores proponen utilizar un esquema en que no siempre se enmascaren los tokens. Este esquema se basa en tres casos, al seleccionar un token de manera aleatoria se puede hacer lo siguiente:
- Sustituirlo por la etiqueta Mask (enmascarar el token). Esto se realizará el 80% de las veces.
- Sustituir el token elegido por un token aleatorio del vocabulario. Esto se realizará el 10% de las veces.
- Mantener al token (sin ningún tipo de sustitución). Este último caso pasará el 10% de las veces.
Por ejemplo, asumamos que tenemos la cadena "la niña miraba por la ventana" y que aleatoriamente se selecciona el token en la posición 3, esto es se selecciona el token "miraba". Puede pasar, por tanto, que:
- Se enmascare la palabra (80% de las veces):
la niña [MASK] por la ventana - Se sustituya por un token aleatorio, por ejemplo "salta" (10% de las veces):
la niña salta por la ventana - Se mantiene el token (10% de las veces):
la niña miraba por la ventana
El modelo del lenguaje buscará predecir el token que ha sido enmascarado, cuando éste sea el caso. Para cada token, la salida será la probabilidad del mismo token; si el token está enmascarado, se buscará predecir la palabra que puede ocupar ese lugar con mayor probabilidad. Se suelen utilizar etiquetas extras CLS (al principio de la oración) y Sep (al final de la oración) que parecerían jugar un papel similar a las etiquetas de inicio y final. Sin embargo, desempeñan un papel diferente. La etiqueta Sep es un separador que indica donde termina una oración y empieza otra y será de gran importancia para la tarea de predicción de la siguiente oración. Por su parte, la etiqueta CLS, si bien se suele colocar al inicio de la cadena, busca indicar que en esa posición se encuentra una representación (un vector) que codifica a la cadena completa (en tanto esta es bidireccional) y por tanto es esta representación la que se usa para tareas de clasificación. Es decir, si queremos realizar una tarea de clasificación (como detección de spam) será el vector correspondiente a CLS el que utilizaremos como entrada para esta tarea.
La Figura de abajo muestra la intuición detrás del modelo enmascarado: dada una cadena enmascarada, el modelo de BERT buscará reproducir la cadena de entrada, pero sustituyendo la etiqueta de enmascaramiento por el token adecuado. Es claro que palabras que aparezcan en contextos similares tendrán una representación similar. Detrás del modelo de BERT, entonces, podemos ver que se encuentra plasmada la hipótesis distribucional.
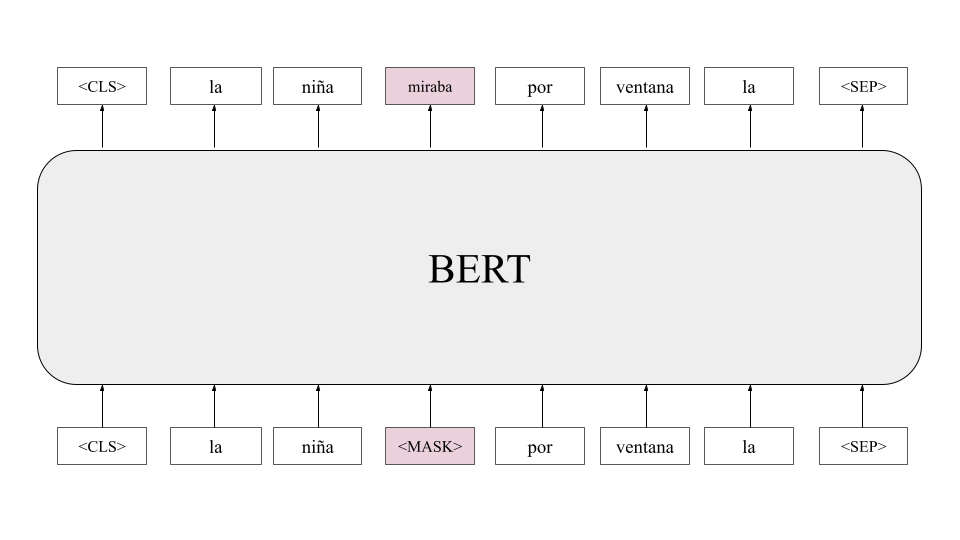
Predicción de la siguiente oración: Para complementar el modelo del lenguaje enmascarado, el pre-entrenamiento incluirá una tarea de predicción de la oración siguiente. Para esto, cada oración terminará con una etiqueta Sep que funciona como un separador entre la oración actual y la siguiente. En general, el modelo de BERT toma como entrada dos oraciones consecutivas (y no sólo una como otros modelos). De esta forma, una cadena de entrada estará conformada por dos oraciones, por ejemplo:
`[CLS] fue a la tienda [SEP] compró un litro de leche [SEP]`
La primera oración es "fue a la tienda" seguida de la oración "compró un litro de leche". Estas dos oraciones conformaría, dentro del corpus, dos oraciones separadas. La etiqueta Sep indica esto. Al entrenar de esta forma, el modelo toma en cuenta mayor contexto y encadena las oraciones consecutivamente. Así por ejemplo, la siguiente entrada podría ser:
`[CLS] compró un litro de leche [SEP] se fue de allí [SEP]`
A partir de estas dos cadenas de entrada, el modelo es capaz de relacionar la oración "se fue de allí" con la oración "fue a la tienda" a partir de la oración intermedia ("compró un litro de leche"). A estas cadenas, además, se les aplica enmascaramiento. Pero además del modelo del lenguaje, se propone que el pre-entrenamiento realice una predicción. Se predice si la oración que viene después de Sep es la oración siguiente (dentro del corpus) o si no lo es. Por ejemplo, las dos oraciones anteriores serían clasificadas como $IsNext$ en tanto corresponde a una secuencia correcta de oraciones dentro del corpus.
Para generar ejemplos negativos, se emparejan secuencias de manera aleatoria. Por ejemplo, dada la oración "fue a la tienda", se selecciona aleatoriamente otra oración no consecutiva dentro del corpus. A estas parejas de oraciones se les etiqueta como $NotNext$. De tal forma que el pre-entrenamiento realiza una calificación binaria entre dos series de etiquetas $IsNext$ y $NotNext$.
Para identificar de manera adecuada las posiciones de las sentencias se utiliza una codificación que indica si un token pertenece a la primera o segunda oración. Esta codificación es adicional a la codificación posicional de los Transformers y la revisaremos a continuación.
Implementación del modelo de BERT¶
La implementación del modelo de BERT utiliza únicamente la parte de decodificador del Transformer, por lo que utiliza la auto-atención para las cabezas del modelo. La implementación que se sigue esmuy simple y consta de las siguientes subcapas:
- Embeddings y codificación posicional
- Cabezas de auto-atención
- Suma y normalizción
Al final, la clase regresará el vector de clasificación cls así como los vectores contextualizados que salen por cada token de entrada. Esto permite que el modelo se pueda utilizar tanto para tareas de clasificación como para modelos del lenguaje enmascarados, adaptando una capa de salida que sea pertinente para cada caso. En este caso, descartamos la subcapa de feedforward, la cual se puede integrar como un ejercicio para comparar el desempeño del modelo.
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
from tqdm import tqdm
from copy import deepcopy
from transformers_functions import *
from transformers import AutoTokenizer
class SimpleBERT(nn.Module):
def __init__(self, input_size, d_model=128, heads=3, p=0.3):
super().__init__()
#Embeddings y codificación posicional
self.embs = nn.Embedding(input_size, d_model)
self.pos = PositionalEncoding(d_model)
#Cabezas de atención
self.att = nn.ModuleList([deepcopy(SelfAttention(d_model)) for _ in range(heads)])
#Capa lineal
self.lin = nn.Linear(heads*d_model, d_model)
#Auxiliares
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.drop1 = nn.Dropout(p)
self.drop2 = nn.Dropout(p)
def forward(self, x):
#Creación de entradas
x_e = self.embs(x)
x_e += self.pos(x_e)
x_e = self.drop1(self.norm1(x_e))
#Aplicación de cabezas de atención
head_att = [head(x_e) for head in self.att]
self.att_weights = [head[1] for head in head_att]
heads = [head[0] for head in head_att]
#Aplanamiento de cabezas
multi_heads = torch.cat(heads, dim=-1)
h = self.lin(multi_heads)
h = self.drop2(self.norm1(h) + x_e)
#Vector de clasificación
cls = h[:, 0]
return cls, h
Carga de datos¶
Para probar el modelo, hacemos uso de los datos de clasificación de texto en sentimiento sobre el Coronavirus. Estos datos se encuentran disponibles en la página de Kaggle: https://www.kaggle.com/datasets/datatattle/covid-19-nlp-text-classification. Estos datos cuentan con etiquetas en 5 sentimientos, desde muy negativo hasta muy positivo, pasando por neutro.
Para procesar los datos, se utiliza únicamente el texto del tweet y la clasificación. Se hace uso del símbolo cs que, usualmente, es el primer elemento que aparece en la cadena de texto; por lo que toda cadena de texto tendrá la forma: $$[cls] \text{ } w_1 w_2 ... w_n$$ Donde cada $w_i$ es un token. Todas las palabras se tokenizan utilizando el tokenizador de BERT (bert-base-uncased), utilizando que se encuentra en la paquetería de transformer de Hugging Face. Finalmente, se crean los lotes con cargadores de datos para el entrenamiento y la evaluación.
#Lectura de los datos de texto
data = pd.read_csv('SentimentCOVID/Corona_NLP_train.csv', encoding='latin1')
dataX = data['OriginalTweet'].tolist()
dataY = data['Sentiment'].tolist()
#Etiquetas
labels = {'Extremely Negative':4, 'Extremely Positive':3, 'Negative':2, 'Neutral':0, 'Positive':1}
y = [labels[l] for l in dataY]
#tokenización y símbolo de clase
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
voc = vocab()
voc['[cls]'] = 0
tokens = [['[cls]'] + tokenizer.tokenize(data_i) for data_i in dataX]
x = list(index(tokens, voc))
print(len(x), len(y))
#Cargadores para entrenamiento y test
train_loader, test_loader = get_dataset(x, y, pad=len(voc), batch_size=256)
print(train_loader.dataset.x.shape, train_loader.dataset.y.shape)
41157 41157 torch.Size([28809, 247]) torch.Size([28809])
/home/cienciasia/Documentos/Proyectos/BERT_Prueba/transformers_functions.py:10: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.detach().clone() or sourceTensor.detach().clone().requires_grad_(True), rather than torch.tensor(sourceTensor). self.x = torch.tensor(nn.utils.rnn.pad_sequence(x, padding_value=pad)).T #x
Entrenamiento del modelo¶
Finalmente, ya con el modelo definido y los datos cargados, se puede entrenarel modelo. Además del modelo de atención, se genera un modelo clasificador, que tomará el vector de clasificación cls para clasificar el texto en su clase correspondiente. Para el entrenamiento, se utiliza la función objetivo de entropía cruzada y el optimizador Noam.
model = SimpleBERT(input_size=len(voc)+1)
classifier = nn.Sequential(nn.Linear(128, 256), nn.ReLU(),
nn.Linear(256, len(labels)), nn.Softmax(-1))
model.load_state_dict(torch.load('bert_class.model', weights_only=True))
classifier.load_state_dict(torch.load('classifier_for_bert.model', weights_only=True))
model
SimpleBERT(
(embs): Embedding(20909, 128)
(pos): PositionalEncoding()
(att): ModuleList(
(0-2): 3 x SelfAttention(
(Q): Linear(in_features=128, out_features=128, bias=False)
(K): Linear(in_features=128, out_features=128, bias=False)
(V): Linear(in_features=128, out_features=128, bias=False)
)
)
(lin): Linear(in_features=384, out_features=128, bias=True)
(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(drop1): Dropout(p=0.3, inplace=False)
(drop2): Dropout(p=0.3, inplace=False)
)
criterion = nn.CrossEntropyLoss()
optimizer = NoamOptimizer(list(model.parameters())+list(classifier.parameters()), 128, init_lr=0.01, decay=1e-3, warmup=40000)
epochs = 10
model.train()
classifier.train()
for epoch in range(epochs):
for xi, yi in tqdm(train_loader):
optimizer.zero_grad()
cls, probs = model(xi)
output = classifier(cls)
loss = criterion(output, torch.tensor(yi))
loss.backward()
optimizer.step()
print(f'Epoch {epoch}, Loss: {loss.item():.4f}')
0%| | 0/113 [00:00<?, ?it/s]/tmp/ipykernel_10518/2002833018.py:13: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.detach().clone() or sourceTensor.detach().clone().requires_grad_(True), rather than torch.tensor(sourceTensor). loss = criterion(output, torch.tensor(yi)) 100%|█████████████████████████████████████████| 113/113 [01:36<00:00, 1.17it/s]
Epoch 0, Loss: 1.4078
100%|█████████████████████████████████████████| 113/113 [01:44<00:00, 1.08it/s]
Epoch 1, Loss: 1.3841
100%|█████████████████████████████████████████| 113/113 [01:44<00:00, 1.08it/s]
Epoch 2, Loss: 1.3567
100%|█████████████████████████████████████████| 113/113 [01:44<00:00, 1.08it/s]
Epoch 3, Loss: 1.3753
100%|█████████████████████████████████████████| 113/113 [01:44<00:00, 1.08it/s]
Epoch 4, Loss: 1.3589
100%|█████████████████████████████████████████| 113/113 [01:48<00:00, 1.05it/s]
Epoch 5, Loss: 1.3678
100%|█████████████████████████████████████████| 113/113 [01:42<00:00, 1.10it/s]
Epoch 6, Loss: 1.3996
100%|█████████████████████████████████████████| 113/113 [01:41<00:00, 1.11it/s]
Epoch 7, Loss: 1.3932
100%|█████████████████████████████████████████| 113/113 [01:42<00:00, 1.11it/s]
Epoch 8, Loss: 1.4183
100%|█████████████████████████████████████████| 113/113 [01:41<00:00, 1.12it/s]
Epoch 9, Loss: 1.3751
Evaluación¶
Para determinar el desempeño del modelo se evalúa con la partición de los datos correspondiente. Se realiza un reporte de clasificación para obtener los valores de preción, exhaustividad y valor $F_1$.
from sklearn.metrics import classification_report
model.eval()
classifier.eval()
x_pred = []
y_labels = []
for xi, yi in tqdm(test_loader):
x_pred += list(classifier(model(xi)[0]).argmax(1).detach().numpy())
y_labels += list(yi.numpy())
print(classification_report(x_pred, y_labels, target_names=['Neutral', 'Positive', 'Negative',
'Extremely Positive', 'Extremely Negative']))
100%|██████████████████████████████████████| 1235/1235 [00:09<00:00, 134.88it/s]
precision recall f1-score support
Neutral 0.83 0.50 0.62 3833
Positive 0.55 0.54 0.55 3521
Negative 0.46 0.52 0.49 2614
Extremely Positive 0.52 0.73 0.61 1420
Extremely Negative 0.36 0.61 0.45 960
accuracy 0.55 12348
macro avg 0.54 0.58 0.54 12348
weighted avg 0.60 0.55 0.56 12348
torch.save(model.state_dict(), 'bert_class.model')
torch.save(classifier.state_dict(), 'classifier_for_bert.model')