Implementación de Backprop con gráficas computacionales¶
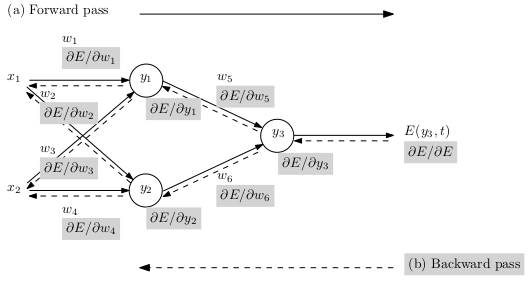
El entrenamiento en redes neuronales requiere de la optimización de una función de riesgo, por lo que se hace necesario obtener las derivadas de esa función de riesgo. Para esto, se implementa el algoritmo de backpropagation que es un algoritmo de diferenciación automática, el cual permite obtener las derivadas de la función de riesgo sobre una red neuronal.
Algortimo para aprendizaje en red neuronal¶
Entrenaremos nuestra red neuronal utilizando el siguiente algoritmo:

La parte central del algoritmo está en el backpropagation. Esto nos permite implementar las derivadas para poder actualizar los pesos de toda la red.
Para implementar el backpropagation utilizaremos una gráfica computacional.